Bilgisayar Çağı’nın Yeni Sömürü Modeli: Kitle Kaynaklı Çalışma-“Amazon Mechanical Turk” örneği
Crowdsourcing: The New Exploitation Model of The Computer Age - The “Amazon Mechanical Turk” Example
Bilim ve Aydınlanma AkademisiKolektif Yaşamı Kurgulama Bilim Alanı - Bilişim Teknolojileri Komisyonu
Özet
Yapay zeka teknolojilerinin endüstride ve günlük hayatta daha çok kullanılır hale gelmesinin merkezinde duran faktörlerden biri büyük miktarda verinin kolayca üretilebilir ve erişilebilir olmasıdır. Kısaca “büyük veri” diyebileceğimiz bu değeri, amorf bir veri yığını olarak düşünmemek gerekir. Büyük miktarda verinin yapay zeka teknolojileri açısından faydalı olabilmesi için çoğu zaman bu verinin temizlenmesi, işlenmesi veya etiketlenmesi gerekir. Önemli bir vasıf gerektirmeyen bu veri işçiliği, günümüzde teknoloji tekelleri tarafından ‘’kitle kaynaklı çalışma’’ (İng. crowdsourcing) modeline havale edilmiştir. Bu çalışma modelinin öncüsü ve en önemlisi olan Amazon Mechanical Turk’ü (AMT), teknoloji tekelleri ticari ürünlerini geliştirmek için sıkça kullanmaktadır. Çalışma koşullarının hiçbir regülasyona tabi olmadığı AMT, “çalışanlarının” sınırsız sömürüsüne olanak sağlamaktadır. 2017 yılında yapılan bir araştırmaya göre AMT çalışanının medyan geliri saatte 2 dolardı. Aynı yılda Amerika Birleşik Devletleri’ndeki federal asgari ücretin saatte 7,25 dolar olması, AMT’nin çalışma koşulları hakkında önemli bir fikir vermektedir. Böylece, dünyanın “en zengin ve havalı” teknoloji şirketleri, çalışma koşulları 19. yy.’daki tekstil işçilerininkine benzetilen bir çalışma modeli ile büyümektedir.
Anahtar kelimeler: kitle kaynaklı çalışma, sömürü, yüksek teknoloji, amazon mechanical turk.
Abstract
A major factor behind the increasing use of artificial intelligence technologies in industry and daily life is the ease in production of and accessibility to large amounts of data. This asset, which we can call “big data”, is not just an amorphous stack. For large amounts of data to be useful for artificial intelligence technologies, it is often necessary to clean, process or annotate them. These mundane tasks, which do not require specific skills, are delegated to crowdsourcing by the technology monopolies today. The pioneer of this crowdsourcing labor model, the Amazon Mechanical Turk (AMT), is being used by many technology monopolies in the development of actual products. The working conditions in AMT are not subject to any regulations at all, hence it enables unlimited exploitation of its “workers”. According to a research study carried out in 2017, the median hourly income for an AMT worker was 2 US dollars. At the same year, the federal minimum wage in the US was 7.25 US dollars, which signifies poor working conditions in AMT. Thus, the richest and “coolest” technology monopolies in the world are growing based on a working model which is likened to that of 19th century textile workers’.
Key words: crowdsourcing, exploitation, advanced technology, amazon mechanical turk.
Giriş
Ünlü matematikçi ve bilgisayar bilimcisi Alan Turing’in "makineler düşünebilir mi?" sorusunu ortaya atmasının üzerinden 72 yıl geçti (Turing, 1950). Bu süre zarfında “yapay zekâ” (YZ) araştırmalarında sibernetik, otomata teorisi, mantık ve sembolik akıl yürütme, kural tabanlı sistemler gibi birçok farklı paradigma ortaya çıktı. Bu paradigmalardan biri olan “makine öğrenmesi” veya ”yapay öğrenme” (İng. machine learning), son yıllarda YZ araştırmalarında baskın yaklaşım haline geldi. Kısaca “bilgisayarın örneklere bakarak kendi kendini programlaması” olarak tanımlayabileceğimiz yapay öğrenme yaklaşımının son yıllardaki ivmeli yükselişini akademik alanda kolayca gözlemek mümkün (Şekil 1). Benzer şekilde, yapay öğrenmenin etkisi endüstride de görülmekte (Şekil 2) ve bu yaklaşımla elde edilmiş ürünler her geçen gün daha çok hayatımıza girmektedir. Üretim bandındaki akıllı robotlar, endüstrinin her seviyesindeki otomasyon, dilden dile otomatik çeviri, akıllı asistan uygulamaları, tıbbi teşhis uygulamaları, otonom araçlar gibi güncel YZ uygulamalarının hemen hepsinin yapay öğrenme tabanlı olduğunu söylemek abartılı olmayacaktır.


YZ’nin bir alt dalı olan “yapay öğrenme”yi örnek bir problem üzerinden tanımaya çalışalım. Amacımız, trafikte giderken etrafında gördüğü nesneleri tanıyan akıllı bir araç kamerası geliştirmek olsun. Trafikteki diğer araçlar, yayalar, bisikletli insanlar, trafik levhaları, yoldaki şeritler, kaldırımlar, bitkiler gibi bir insanın etrafına baktığında hiç efor sarfetmeden tanıyabileceği nesneleri otomatik olarak tanıyabilen bir YZ sisteminden söz ediyoruz. Problemi basitleştirmek için sadece trafik levhalarına, hatta sadece “Dur” levhasını tanımaya odaklanalım. Kameranın (bilgisayarın) bu levhayı tanıyabilmesi için levhanın şu özelliklerini tespit etmesinin yeterli olacağı düşünülebilir: görüntüdeki piksellerin çoğu kırmızı renkte olmalı, altıgen bir şekil olmalı, “D” “U” ve “R” harfleri bulunmalı. Fakat sokaktan alınan görüntülerde bu özelliklerin tespitini zorlaştıracak birçok etmen vardır: örneğin, levhanın rengi solmuş olabilir; görüş açısı, uzaklık, hava koşulları (sis, yağmur, kar, vb.) ve ışık miktarı, altıgen şekli ve harfleri algılamayı zorlaştırabilir. Sadece bunlar değil, aynı sistemin onlarca diğer levhayı ve diğer tüm nesne kategorilerini (yaya, araç, bisiklet, vb.) de tanıması gerektiği düşünülürse bu yaklaşımın başarısız olacağını öngörmek zor olmayacaktır. “Kural tabanlı” olarak isimlendirebileceğimiz bu yaklaşım, YZ tarihinin erken zamanlarında kullanılırdı. Şimdi aynı problemi “yapay öğrenme” ile nasıl çözebiliriz diye bakalım. Bu yaklaşımda, önce, sistemimizin tanımasını istediğimiz tüm nesne kategorileri için bol miktar örnek görüntü toplarız. Örneğin, “Dur” levhası için bu levhanın değişik görüş açılarından, farklı hava ve ışık koşullarında çekilmiş mümkün olduğu kadar çeşitli ve mümkün olduğu kadar fazla görüntü toplanmalıdır. Diğer nesne kategorileri için de aynı şekilde görüntü toplanmalıdır. Sonra, bu örnek görüntülerin her bir pikselinin hangi nesne kategorisine ait olduğu etiketlenmelidir. Ardından, verilen görüntüdeki nesneler hakkında tahminler üretebilen parametrik bir fonksiyon tanımlanır. Günümüzde bu fonksiyonlar çoğu zaman derin yapay sinir ağları ile gerçeklenir. Ve bu fonksiyonun parametreleri, etiketli görüntülerde en iyi tanıma başarımını verecek şekilde bilgisayar tarafından otomatik olarak optimize edilir. Bu optimizasyon safhasına “eğitim” adı verilmektedir. Böylece sistemimiz, etiketlediğimiz nesneleri otomatik olarak tanıyacak şekilde ayarlanmış olur. Artık bu sisteme, daha önce hiç görmediği etiketsiz bir görüntü verebilir ve bu girdi görüntüsündeki nesneleri tahmin etmesini isteyebiliriz. Sistemimizi “eğitmek” için kullandığımız veri kümesi ne kadar büyük ve ne kadar çeşitli olursa sistemin başarımı o kadar iyi olacaktır. Bu problem için özel olarak üretilmiş Cityscapes isimli veri kümesinden örnekleri Şekil 3’te bulabilirsiniz.

Yukarıda örneklediğimiz yapay öğrenme yaklaşımı, kullandığı etiketli veri kümesinden dolayı “gözetimli öğrenme” (İng.supervised machine learning) olarak adlandırılır. Yapay öğrenmenin, “gözetimsiz öğrenme”, “pekiştirmeli öğrenme”, “üretici modeller” gibi birçok alt alanı bulunmaktadır ve bu alt alanlar yazımızın kapsamını aşmaktadır. Burada, “gözetimli öğrenme”nin yapay öğrenmede hakim olan yaklaşım olduğunu ve günlük hayatta gördüğümüz hemen tüm YZ uygulamalarının bu yaklaşımla elde edildiğini söylemekle yetinelim.
Yapay öğrenme tabanlı YZ uygulamalarının endüstride veya günlük hayatta bu kadar çok karşımıza çıkmasını sağlayan faktörler arasında kuşkusuz hızlanan ve yaygınlaşan bilgisayarlar ile araştırmacıların yapay öğrenme yöntem ve modellerini sürekli geliştirmeleri var. En az bunlar kadar önemli olan diğer faktör ise veri. Her geçen gün artan miktarlarda üretilen dijital veriler YZ uygulamalarının geliştirilmesine olanak sağlıyor. Bu veriler o kadar önemli ki, örneğin otonom araç yapmaya çalışan firmalar için modellerini eğittikleri veri kümeleri hem bir ticari sır hem de çok değerli bir varlık niteliğinde. Bu firmalardan biri veri kümesinin muhtemelen çok ufak bir kısmını ticari olmayan kullanım için araştırmacılara açtığında haber olmuştu (Hawkins, 2019).
Çok miktarda verinin faydalı olabilmesi için bu verinin çoğu zaman işlenmesi, temizlenmesi ve etiketlenmesi gerekir. Önemli bir vasıf gerektirmeyen ve “veri işçiliği” olarak adlandırabileceğimiz bu iş, günümüzde teknoloji tekelleri tarafından ‘’kitle kaynaklı çalışma’’ modeline havale edilmiştir. Bu çalışma modelinin öncüsü ve en önemlisi olan Amazon Mechanical Turk’ü (AMT), teknoloji tekelleri ticari ürünlerini geliştirmek için sıkça kullanmaktadır. Hangi firmanın veri kümesini etiketletmek için AMT’yi (veya benzeri başka bir platformu) kullandığı açıkça yayımlanan bir bilgi olmadığı için bir liste vermek zor. Fakat bilinen örnekler yeterince çarpıcı. Toyota ve Massachusetts Teknoloji Enstitüsü ortaklığıyla toplanan bir veri kümesinin AMT kullanarak etiketlendiği biliniyor (Alford, 2020). Yandex, otonom sürüş veri kümesini AMT benzeri bir ‘’kitle kaynaklı çalışma’’ platformu olan Toloka ile etiketledi (Toloka, 2020). Yine AMT benzeri ScaleAI isimli bir firmanın 2018 yılında veri etiketleme işi için 18 milyon dolarlık yatırım aldığı ve bu firmanın, aralarında General Motors ve Lyft’in olduğu birçok firmanın otonom sürüş verilerini etiketlediği basına yansımıştı (Megorskaya, 2021). Veri etiketleme sektörünün 2028’de 8,22 milyar dolarlık bir büyüklüğe ulaşacağı öngörülüyor (Megorskaya, 2021). Şimdiye kadar verdiğimiz örnekler hep otonom sürüş üzerine olsa da AMT ve benzeri platformlar çok çeşitli veri kümelerinin etiketlenmesi için kullanılıyor.
Amazon Mechanical Turk (AMT) nedir?
Amazon sitesi 1991 yılında yaşamına kitap satışıyla başladı. 2000’li yılların başında ise her türlü ürünü site üzerinden satmaya başlayarak bugün binlerce örneği olan e-ticaret sitelerinin öncülerinden oldu. Bu kadar çok ürünün siteye eklenmesi ciddi bir sorunu beraberinde getiriyordu. Ürünler site envanterine girmişti ancak yapısal olarak dağınıktı, sınıflandırılmış bir ürün yapısı bulunmuyordu. Onbinlerce ürünün aynılarının ayıklanması gerekiyordu.
Firmanın mühendisleri tekrar eden ürünlerin ikincil kopyalarını tespit edecek bir yazılım geliştirmeye başladılar. Ancak kısa sürede bu problemi “aşılamaz” olarak nitelendirip çalışmayı durdurdular. Ürünler için hazırlanmış metin ve görselleri inceleyerek iki ürünün aynı olup olmadığına karar vermek insan zekası için çok kolay bir iş olduğu halde, bilgisayarlar bu problemi çözemiyordu.
Sonuç olarak ayıklama işinin ancak insan gücüyle çözülebileceği anlaşılmıştı. Yalnız ürün sayısı fazlaydı ve çözümün uygulanması büyük bir işgücü gerektiriyordu. Bu sefer problem yüksek sayıda insanın bu ayıklamayı yapmak için nasıl koordine edileceğiydi.
Amazon yöneticilerinden Venky Harinarayan çözüm için “hibrit makine/insan hesaplama düzeni” (İng. Hybrid machine/human computing arrangement) adlı bir çalışma sistemi önerdi (Harinayan ve ark., 2007). Bu sisteme göre iş alt parçalara ayrılacak şekilde tarif edilir, sistem işi insanlara dağıtır, her bir çalışan kendi işini tamamlayınca yaptıklarını sisteme geri gönderir ve böylece problem küçük parçalar halinde çözülmüş olur.
Bu çözüm yöntemi Amazon’un problemi için çok iyi çalıştı. Çalışanlar kısa sürelerde tüm tekrar ürünleri sildiler, sınıflandırdılar. Amazon bu yöntemin firma için muazzam başka avantajları olduğunu farketti. Çalıştıkları insanları işe alması ve hatta görmesi bile gerekmiyordu. Çok sayıda insan kendi bilgisayarlarından herhangi bir yerde, herhangi bir saatte çalışabiliyordu.
O tarihlerde Amazon’un yöneticiliğini yapan Jeff Bezos yüksek vasıf gerektirmeyen bu iş modelinin geliştirilerek satılabileceğini farketti. İnsan Zekası Görevleri (İng. HIT: Human Intelligence Tasks) olarak tanımlanan bu hizmet Amazon Mechanical Turk (MTurk) ismiyle 2005 yılında dışarıya da servis vermeye başladı.
Amazon bu ürününün ismini Mechanical Turk (Türk Otomatı) olarak bilinen tarihi bir hikayeden seçmiştir. 1770'de mekanikçi Wolfgang von Kempelen tarafından Viyana İmparatoriçesi Maria Theresa için satranç oynayan bir otomat geliştirilmiştir (Şekil 4). 120x105x60 boyutlarında üzerine satranç tahtası çizilmiş tekerlekli bir kabinet önünde oturan bıyıklı, sarıklı ve pelerinli bir Türk figürü olan makine, satranç hamlelerini yapabiliyor ve birçok rakibini yeniyordu (“Mechanical Turk”, 2022). Satrancı oynayan tabi ki makine değil, kabinetin içine ustalıkla saklanmış bir insandı.

Yukarıdaki hikayenin özüne benzer şekilde Amazon Mechanical Turk (AMT) hizmetinden yararlananlar için otomatik işleyen, görünmeyen kısmında ise insan emeği ve bilgisi gerektiren bir sistem vardır.
Kısa süreli, çok sayıda insana gereksinim duyulan ve doğal zeka gerektiren işler için bu yapının bir hizmet olarak pazarlanmaya başlaması kısa sürede karşılık buldu. Elindeki büyük verisinin belirli bir şekilde işlenmesine ihtiyaç duyan firmalar AMT yapısını kullanarak problemlerini kolayca ve hızlıca çözmeye başladı.
Bugün onlarca benzeri olan AMT kitle kaynaklı çalışmanın öncülerindendir ve en büyüklerinden biri olmayı sürdürmektedir.
“Kitle Kaynaklı” çalışma modeli
Kitle kaynak kullanımı genel anlamıyla mal veya hizmetlerin üretiminin geniş ve dağınık işgücüyle yapılması olarak özetlenebilir. Bu çalışma modelinin ilk uygulamasını 1985’te DialAmerica şirketinin yaptığı söylenebilir. Şirket evlere üzerinde isimler yazılı kartlar göndermiş ve her isim için doğru telefon numarasını bulup yazma işi için parça başına ücret ödemiştir. Bir işçinin açtığı dava üzerine mahkemeler bu işçilerin aslında Adil Çalışma Standartları Yasası uyarınca asgari ücrete hak kazandıklarına karar vermiştir (Irani ve Silberman, 2013).
Bu ilk örnekten sonra dijital platformlarda kullanılan kitle kaynaklı çalıştırma modeli genellikle internet, sosyal medya ve akıllı telefon uygulamaları aracılığıyla büyük bir insan grubundan iş, bilgi, ve/veya fikir almayı içermektedir. Bu modeli kullanan CrowdFlower, Toluna ve Amazon gibi emekçilerle işverenleri dijital bir platformda buluşturan şirketler olabildiği gibi NASA Clickworker (Mars’ın yaş haritası bu yöntemle çıkarılmıştır), Wikipedia gibi çeşitli amaçlarla gönüllü havuzu oluşturan ya da WAZE gibi varolan müşterisinden gönüllü olarak veri toplayan kurumlar da vardır. (NASA, 2001).
Bu modelde bir kurumun yapılmasını istediği İnsan Zekası Görevleri (İZG) AMT gibi dijital bir platform üzerinden sunulur. Emekçiler bu platformlara üye olurlar ve listelenen görevleri Şekil 5’te örneği verilen bilgileri değerlendirerek inceler, aralarından seçim yapar ve seçtikleri görevleri tamamlarlar.
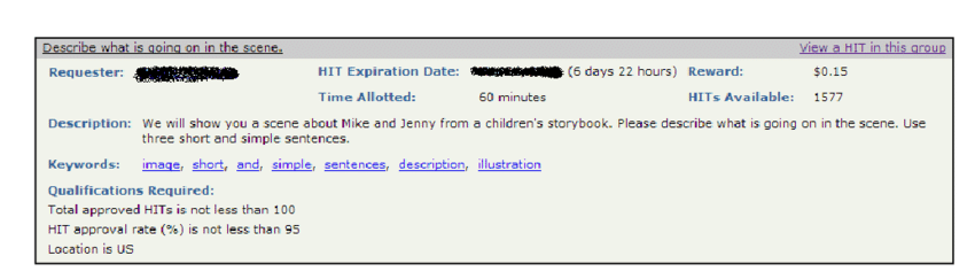
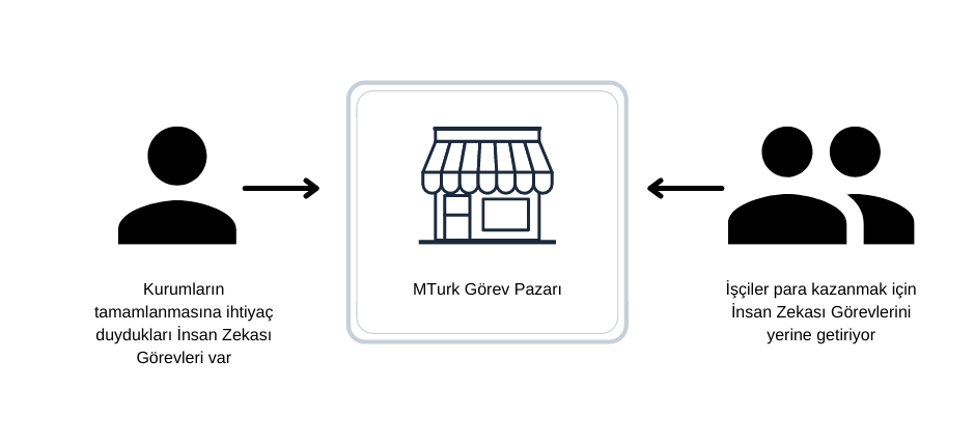
Tanımladığı İnsan Zekası Görevlerinin yapılmasını talep eden kurum yapılan görevleri kontrol eder ve onayladıktan sonra AMT üzerinden ücret ödemesi gerçekleştirilir. Amazon talep eden kurumun işçilere ödediği ücretin %20’si oranında şirketten komisyon alır. Bu durumda AMT gibi platformlar Şekil 6’da gösterildiği gibi bir görev pazarı rolü üstlenmektedir.
Günümüzde kitle kaynak uygulamalarına bakıldığında; grafik tasarım gibi yetkinlik isteyen işler için de kullanılmaya başlandığını ancak yaygın kullanımın zor olmayan, yüksek beceri gerektirmeyen “beyin uyuşturucu” işlerde olduğu görülmektedir. Burada işveren için cazip olan hiçbir yasal düzenlemeye uyma zorunluluğu olmadan, 7/24 hazır ve geniş işgücü havuzuna erişim ve dolayısıyla çok çok düşük ücret karşılığında son derece esnek çalışma koşullarıdır. Şekil 7 Amazon Mechanical Turk iş modelini özetlemektedir.

2.676 çalışanın tamamladığı 3,8 milyon iş üzerinden yapılan bir araştırma, ortalama ücretin saatte 2$ olduğunu göstermiştir (Hara ve ark., 2018). Bu hesaba, çalışanın varolan işleri incelemesi, onlardan uygun olanları belirlemesi için gereken zaman ya da üzerinde çalıştığı halde işveren tarafından kabul edilmeyen işlerin dahil edilmemiş olduğu düşünüldüğünde emekçiler tarafından elde edilen gelirin bu ücretin de çok çok altında olduğu görülecektir. Yine aynı araştırmada bir AMT çalışanının saatlik medyan gelirinin 2 dolar olduğu ve çalışanların sadece %4’ünün federal asgari ücretten (saatte 7,25 dolar) daha fazla kazandığı gösterilmiştir (Hara ve ark., 2018).
Söz konusu işlerin, boş zamanlarda yapılan işler olarak görünse de, yaşadıkları yerde iş bulma anlamında dijital işlerin tek seçenek haline geldiği emekçiler için esas gelir kaynağı olduğu görülmektedir. Bu tür işlerde çalışanların %25’i yaşadıkları yerlerde başka iş olanağı olmadığı için bu işlerde çalıştıklarını ifade etmiştir. Amerikalıların %5’i bu tür işlerden ücret almaktadır (Semuels, 2018).
Değişen teknoloji, değişmeyen sömürü
Sanayi üretiminin ve ona bağlı olarak modern kapitalizmin gelişiminin ilk evrelerinden itibaren, sermaye emeği kontrol altına almak ve emek maliyetlerini düşürmek için sürekli yeni yöntem ve teknikler geliştirdi. Üretimin tekrara dayalı, rutin ve basit işlere bölünmesi emeğin değersizleşmesine ve emekçinin üretime yabancılaşmasına neden oldu. Buna eşlik eden parça başı iş, taşeron çalışma gibi kuralsız yöntemler sermayenin kârını artırırken emekçileri vasıfsızlık, güvencesizlik ve işsizlik gibi sorunlarla karşı karşıya bıraktı.
Kapitalizmin ilk dönemine damgasını vuran bu sömürü koşullarına karşı işçilerin güçlü mücadelesi ve 20. yüzyıldaki reel sosyalizm uygulamaları sayesinde çalışma süresi, ücretler ve haklar konusunda ciddi kazanımlar elde edildi. İşçi sınıfının örgütlü gücü bu kazanımların bir süre korunmasını sağladıysa da özellikle 1980'li yıllarda ortaya çıkan neoliberal uygulamalarla esnek ve kuralsız çalışma biçimleri giderek yaygınlaştı.
Kapitalizmde teknolojik gelişmenin temel motivasyonu her zaman sömürüyü artırmak oldu. Sanayi devrimi sürecinde makinenin bir parçasına dönüşen işçiler, yaklaşık 200 yıl sonra benzer bir durumu yaşıyor. Bugün gelişen bilişim teknolojileriyle insanlar bilgisayarın bir parçası haline geliyor; en temel çalışma haklarından mahrum, düşük ücretlerle, süresiz, güvencesiz ve yoğun bir rekabet içerisinde hayatta kalmak için çalışıyorlar. Tam da Amazon'a ilham veren "Mechanical Turk" makinesinde olduğu gibi, İnternet'in işleyişinde önemli bir yer tutan yoğun emek görünmez oluyor, Jeff Bezos’un AMT‘yi 2006 yılında MIT izleyicisine anlatırken kullandığı sözlerdeki gibi hizmete dönüşüyor: “Bir hizmet olarak yazılımı duydunuz. Şimdi bu bir “hizmet olarak insan” (İng. human as a service)”. Bu durum pek çok mesleği ortadan kaldıracağı söylenen yapay zeka teknolojilerinin, bir yandan insan emeğine ne kadar muhtaç olduğunu da gösteriyor.
Sömürüsüz gelişim mümkün
Toplumsal ihtiyaçların bilimsel ve akılcı yöntemlerle karşılanmasını temel alan bir siyasal düzen olarak sosyalizm, bu hedefine merkezi planlama ile ulaşır. Geniş bir katılımla hazırlanan ve sonrasında merkezileştirilen planın tüm üretim birimlerine yansıması ve bunlar arasında koordinasyonu (Bilişim Teknolojileri Komisyonu, 2020); aynı zamanda uçtan uca üretilen tüm verinin paylaşımını ve ilişkilendirilmesini de sağlayacaktır. Bu açıdan değerlendirildiğinde, günümüzde planlamanın yokluğundan kaynaklanan karmaşanın sosyalizmde kolayca aşılabileceği; bugün ancak insan emeği ile yeniden anlamlandırılabilen birçok veri kümesinin, daha oluşturulması aşamasında anlamlı bağlantılarla zenginleştirilerek kullanılabileceği veya bu ihtiyaçlar doğrultusunda üretim planlamasının yapılabileceği göz önünde bulundurulmalıdır (örneğin; otonom araçlar için sinyalizasyon sistemleri tasarlama, araçlar arası iletişim protokolleri oluşturma vb.). Bu durum bugün düşük ücretlere gerçekleştirilen tekrara dayalı iş yükünün bir ölçüde azalması anlamına gelecektir.
Öte yandan, her şeye rağmen teknolojik gelişimin yetersiz kaldığı veya işlem kaynak maliyetinin yüksek olduğu durumlarda, kaçınılmaz olarak yine insan emeğine başvurulacaktır. Burada bir işçi sınıfı iktidarıyla yönetilen sosyalist düzende öncelikli olarak bu alanda çalışma kurallarının belirleneceği, dijital emekçilerin diğer tüm emekçiler gibi her türlü güvence ve hakka sahip olarak, tanımlı mesai sürelerinde, hak ettikleri ücretlerle çalışacakları belirtilmelidir. Yine de işin yıpratıcı ve gelişime kapalı doğası göz önünde bulundurulduğunda, bu çalışmanın -bazı diğer kamu hizmetlerinde de olabileceği gibi- toplumsallaştırılması, daha geniş ölçekte daha kısa süreli gönüllü çalışmaya başvurulması gibi farklı yöntemlerin denenmesi gerekecektir. Bu yöntemler, aynı zamanda bu teknolojilerin arkasındaki emeği görünür kılarken, toplumu da üretimin bir parçası haline getirerek, üretilen teknolojinin de toplum tarafından sahiplenilmesinin önünü açacaktır.
Kaynaklar
Alford, A. (2020). MIT and Toyota Release Autonomous Driving Dataset DriveSeg. InfoQ. https://www.infoq.com/news/2020/06/mit-toyota-autonomous-driving/ (Son erişim 15.04.2022)
Bilişim Teknolojileri Komisyonu. (2020). Bilişim Teknolojileri ve Sosyalist Planlama. Bilim ve Aydınlanma Akademisi. https://bilimveaydinlanma.org/bilisim-teknolojileri-ve-sosyalist-planlama/ (Son erişim 15.04.2022)
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., ... & Schiele, B. (2016). The cityscapes dataset for semantic urban scene understanding. In Proceedings of The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 3213-3223).
Hara, K., Adams, A., Milland, K., Savage, S., Callison-Burch, C., & Bigham, J. P. (2018, April). A data-driven analysis of workers' earnings on Amazon Mechanical Turk. In Proceedings of the 2018 CHI conference on human factors in computing systems (pp. 1-14).
Harinarayan, V., Rajaraman, A., & Ranganathan, A. (2007). U.S. Patent No. 7,197,459. Washington, DC: U.S. Patent and Trademark Office.
Hawkins, A. J. (2019). Waymo is making some of its self-driving car data available for free to researchers. The Verge. https://www.theverge.com/2019/8/21/20822755/waymo-self-driving-car-data-set-free-research (Son erişim 15.04.2022)
Irani, L. C., & Silberman, M. S. (2013). Turkopticon: Interrupting worker invisibility in amazon mechanical turk. In Proceedings of the SIGCHI conference on human factors in computing systems (pp. 611-620). https://escholarship.org/uc/item/10c125z3
Mechanical Turk. (2022). In Wikipedia. https://en.wikipedia.org/wiki/Mechanical_Turk (Son erişim 15.04.2022)
Megorskaya, O. (2021). What's Under the 'Hood' of Self-Driving Cars?. Entrepreneur. https://www.entrepreneur.com/article/401261 (Son erişim 15.04.2022)
NASA Clickworker Study. (2021). NASA Ames's experiment in volunteer science. https://web.archive.org/web/20040711055051/http://clickworkers.arc.nasa.gov/top (Son erişim 15.04.2022)
Semuels, A. (2018). The internet is enabling a new kind of poorly paid hell. The Atlantic, 23. https://www.theatlantic.com/business/archive/2018/01/amazon-mechanical-turk/551192/ (Son erişim 15.04.2022)
Toloka. (2020). Toloka Helps Train a Self-driving Car to Detect Surrounding Objects. https://toloka.ai/blog/self-driving/(Son erişim 15.04.2022)
Turing, A. (1950). Computing machinery and intelligence. Mind, Volume LIX, Issue 236, October 1950, Pages 433–460, https://doi.org/10.1093/mind/LIX.236.433.
Zhang, D., Mishra, S., Brynjolfsson, E., Etchemendy, J., Ganguli, D., Grosz, B., Lyons, T., Manyika, J., Niebles, J.C., Sellitto, M., Shoham, Y. & Perrault, R. (2021). The AI Index 2021 Annual Report. AI Index Steering Committee, Stanford Institute for Human-Centered AI, Stanford University.